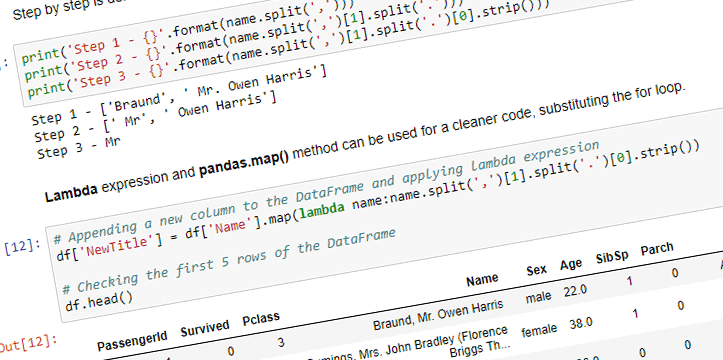
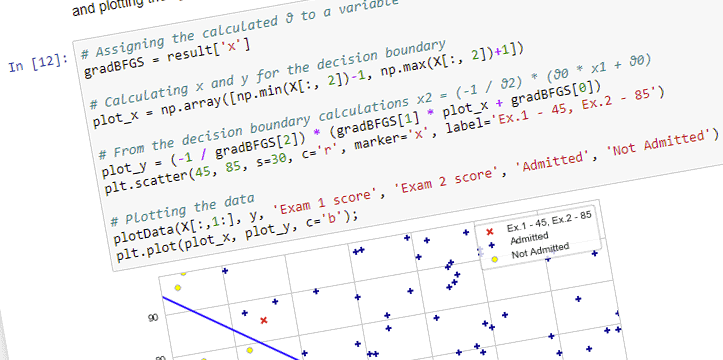
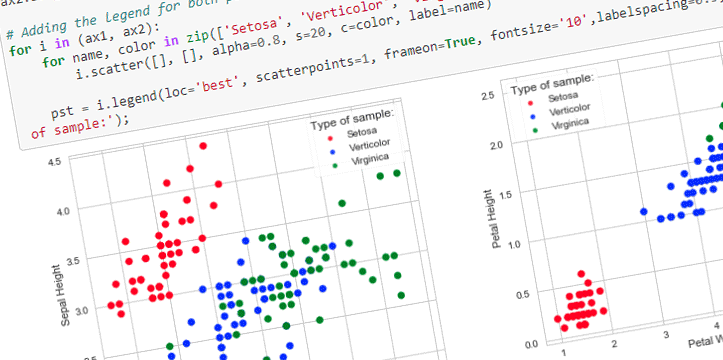
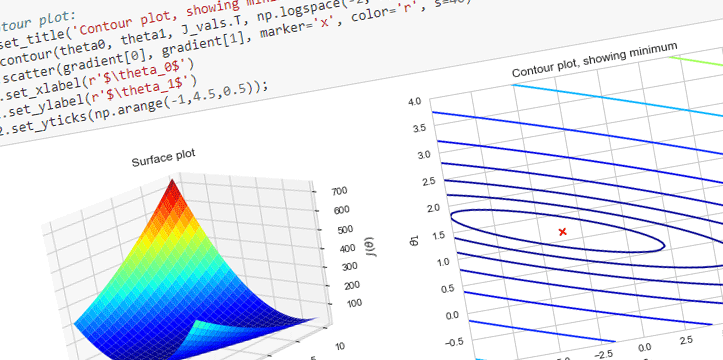
In this blog post we are going to look at Image Recognition with built-in models available in Keras. The notebook can be also viewed on Github.
There are various pre-trained models available in Keras. The weights for these models are trained on a subset of ImageNet dataset. ImageNet is an image dataset containing millions of images with each image described in words. The models are trained on a dataset of 1000 types of common objects (the list of 1000 categories). This dataset is used during The ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
The models for image classification available in Keras are listed below:
- Xception
- VGG16
- VGG19
- ResNet50
- InceptionV3
- InceptionResNetV2
- MobileNet
- DenseNet
- NASNet
Once the model is instantiated, the weights are automatically downloaded to ~/.keras/models/ folder. We will be implementing ResNet50 (50 Layer Residual Network – further reading: Deep Residual Learning for Image Recognition) in the example below. The file containing weights for ResNet50 is about 100MB.
The versions
In this example I am using Keras v.2.1.4 and TensorFlow v.1.5.0 with GPU (using NVIDIA CUDA).