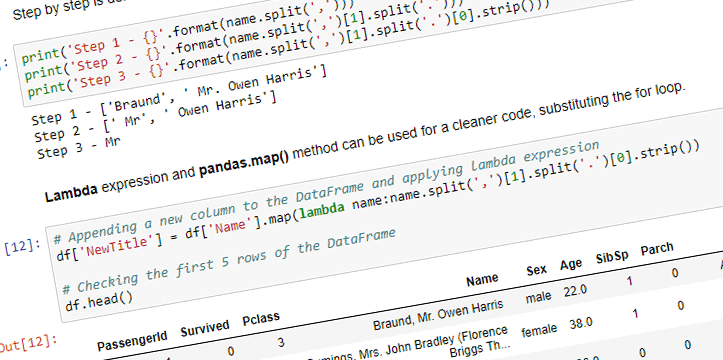
Recently, I was working on some GraphQL data fetching tutorial. The fetched data included time in Unix time format. The author proceeded with 10 minutes writing, in my opinion, unnecessary datetime processing function, to simply display the date output in the certain string format. The function would convert the timestamp to new Date(), extract year, month (which was also converted to display month name based on the corresponding number), date, hour, etc. as variables, and then finally, display it using template literals. The author also used "86400" seconds in adding dates (24 hours, 60 minutes, 60 seconds).
In my experience with Unix time, or in particular Timestamps used in Google Firestore, it is better to avoid writing these type of functions, especially, while dealing with time sensitive data, operations like addition and subtraction of time periods, or dealing with the timezones and daylight saving times.
There are libraries available, like moment-timezone, that make this type of operations easy, and reduce the chance of introducing unnecessary bugs.





 ): Averaging. Mean is a sum of all values divided by the number of values:
): Averaging. Mean is a sum of all values divided by the number of values:
 ): Describes the spread of a distribution. For a set of values, the variance:
): Describes the spread of a distribution. For a set of values, the variance:^2")
 ): Square root of variance, is in the units of the data it represents:
): Square root of variance, is in the units of the data it represents:^2}")