String is a collection of characters. Any character can be accessed by its index. The indexing of a string starts at 0 (or -1 if it’s indexed from the end). We can get the number of characters in a string by using built-in function len. Compared to the indexing, len is not zero based.
# Creating a string
text = 'Some collection of words'
# Assigning the number of characters in the given string to a variable
total_char = len(text)
# Printing the total number of characters
print('Number of characters = {}'.format(total_char))
Let’s look at the indexing of a string. As it has been already mentioned, indexing is zero based. Indexing is in the range (0, 23) while the total amount of characters in the given string is 24. It is demonstrated in the cell below. The characters are looped and printed with the corresponding indices under each character.
{0:3} adds 3 space holders for each character printed. print() function adds new line after it’s executed. By using end=”” we can continue printing on the same line.
# Looping through the characters in the given string
for letter in text:
print('{0:3}'.format(letter), end="")
# Switching to the next line
print()
# Integers are right-aligned by default. We can use '<' to align to the left
for i in range(total_char):
print('{0:<3d}'.format(i), end="")
Similar output but with the old formatting, using the % operator.
for letter in text:
print('%-3s' % letter, end="")
print()
for i in range(len(text)):
index = i - 1
print('%-3s' % i, end="")
String can be sliced. We define slicing from the start index to the last index we need, excluding the last. Also string can be printed backwards:
text[0:10]
text[::-1]
More on the topic:
- Input and Output from the Python tutorials
- Various String Methods
- Formatting the output Tutorial
Example
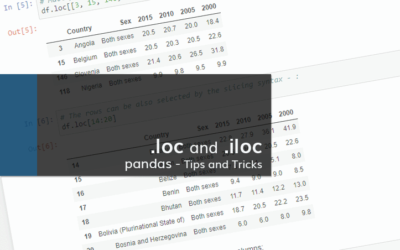
Let’s look at some string methods and their implementation. Kaggle Titanic challenge provides a data set which is split in two different sets (training and test sets). One of the columns provided in the data set contains the names of the passengers. At the first glance it may look like that the column is unusable, but by implementing feature engineering we can extract additional data from this column. If we look closely, we can spot that the names are in the format Last Name, Title, First (and sometimes also Middle name), ex: Braund, Mr. Owen Harris. The data is in string format. We can extract the title from each row of names, and categorize them. One of the solutions available for such problem is shown below:
# Importing pandas library
import pandas as pd
# Loading the given data set to a pandas DataFrame
df = pd.read_csv('data/train.csv')
df.head()
Each name starts with a last name, followed by a comma, and a blank space after comma. Title is followed by a period sign. Using find method, we can detect the position of the characters we are looking for. In this case we are looking for comma (,) and period (.) characters. Let’s look at a single example:
# Creating a string
name = 'Braund, Mr. Owen Harris'
# Detecting the indices of the required characters
name.find(','), name.find('.')
find method shows that the comma is at the index 6, and the period is at the index 10 for the given string. Title for the given string (in this case Mr) can be sliced by using index the range (8, 10).
# Slicing the string
name[name.find(',') + 2 : name.find('.')]
Once the general pattern is available, for loop can be implemented to slice each name in the column to extract the title, and later to save the title to the given DataFrame.
# Creating an empty list to store the titles
array = []
# Looping through the DataFrame
for name in df['Name']:
# Extracting the title by slicing the string
title = name[name.find(',') + 2 : name.find('.')]
# Appending the title to the list
array.append(title)
# Appending the list to the DataFrame under the column 'Title'
df['Title'] = array
# Checking the first 5 titles
df['Title'][:5]
There is another way of achieving the same result by using split and strip methods.
# Creating a string
name = 'Braund, Mr. Owen Harris'
# Applying split and strip methods
name.split(',')[1].split('.')[0].strip()
Let’s apply this way step by step:
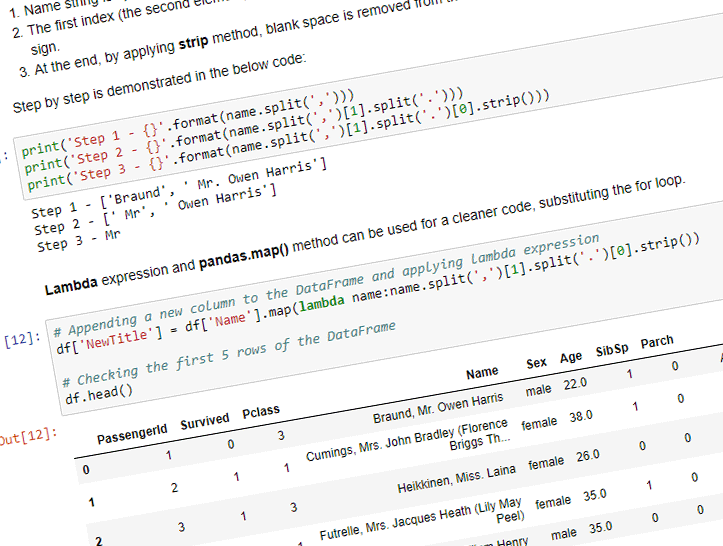
- Name string is split into an array of two strings at the comma sign.
- The first index (the second element) of an array is selected and then split again. This time the new string is split into an array of two strings at the period sign.
- At the end, by applying strip method, blank space is removed from the 0 index of an array.
Step by step is demonstrated in the below code:
print('Step 1 - {}'.format(name.split(',')))
print('Step 2 - {}'.format(name.split(',')[1].split('.')))
print('Step 3 - {}'.format(name.split(',')[1].split('.')[0].strip()))
Lambda expression and pandas.map() method can be used for a cleaner code, substituting the for loop.
# Appending a new column to the DataFrame and applying lambda expression
df['NewTitle'] = df['Name'].map(lambda name:name.split(',')[1].split('.')[0].strip())
# Checking the first 5 rows of the DataFrame
df.head()
Downloadable content: train.csv